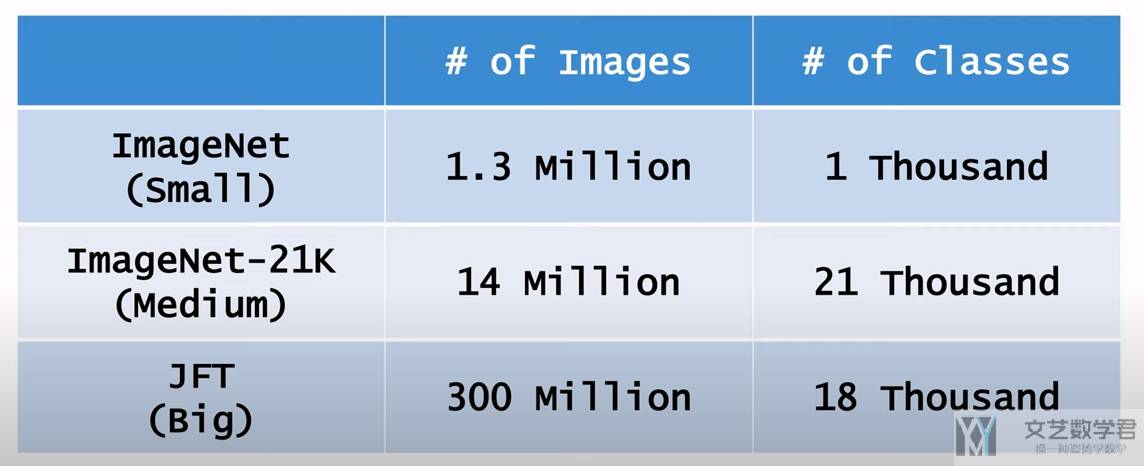
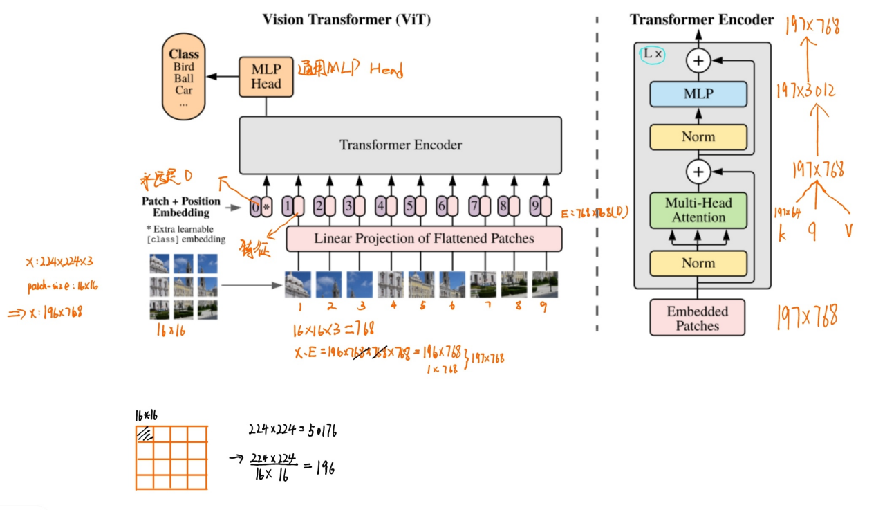
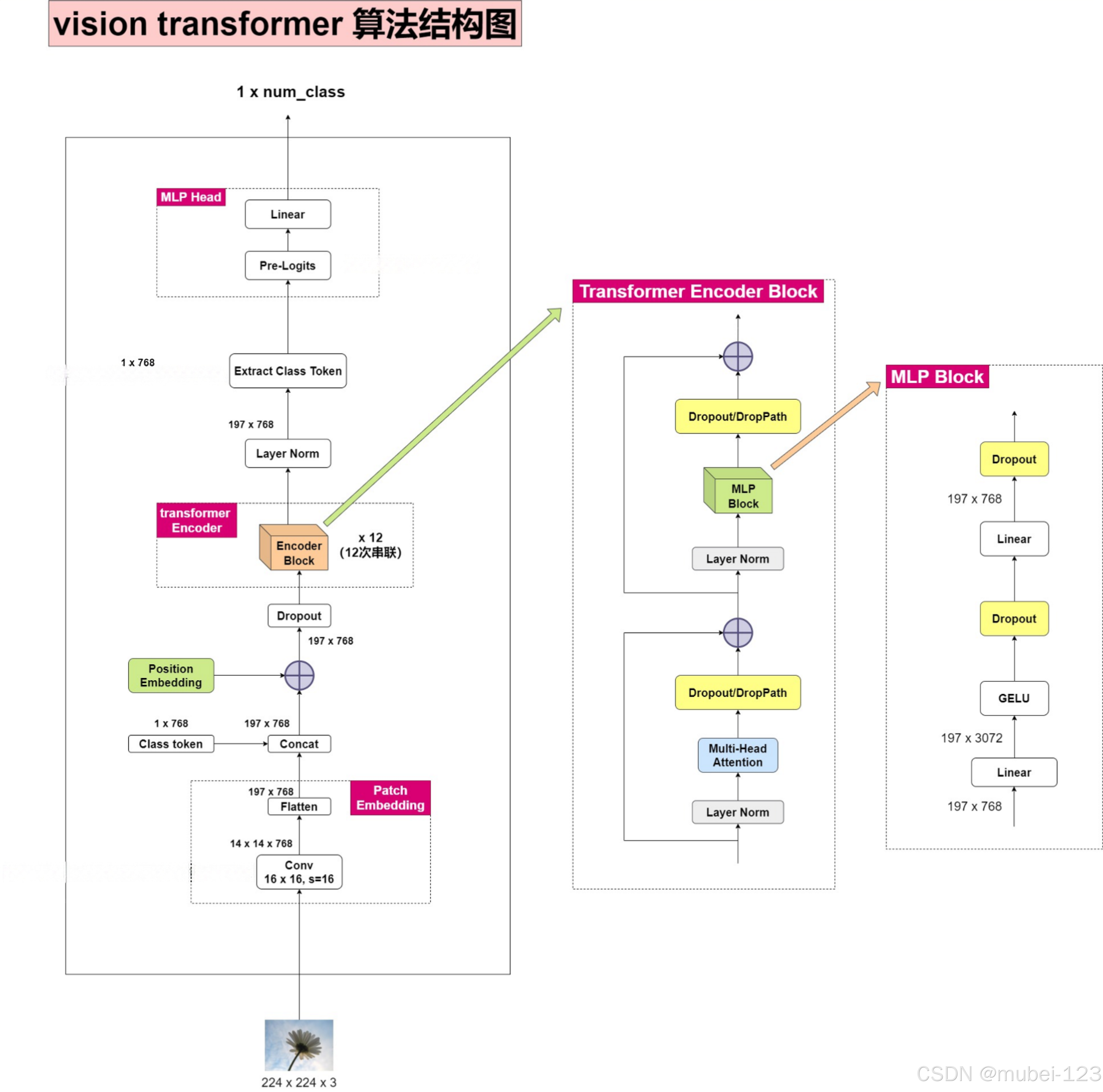
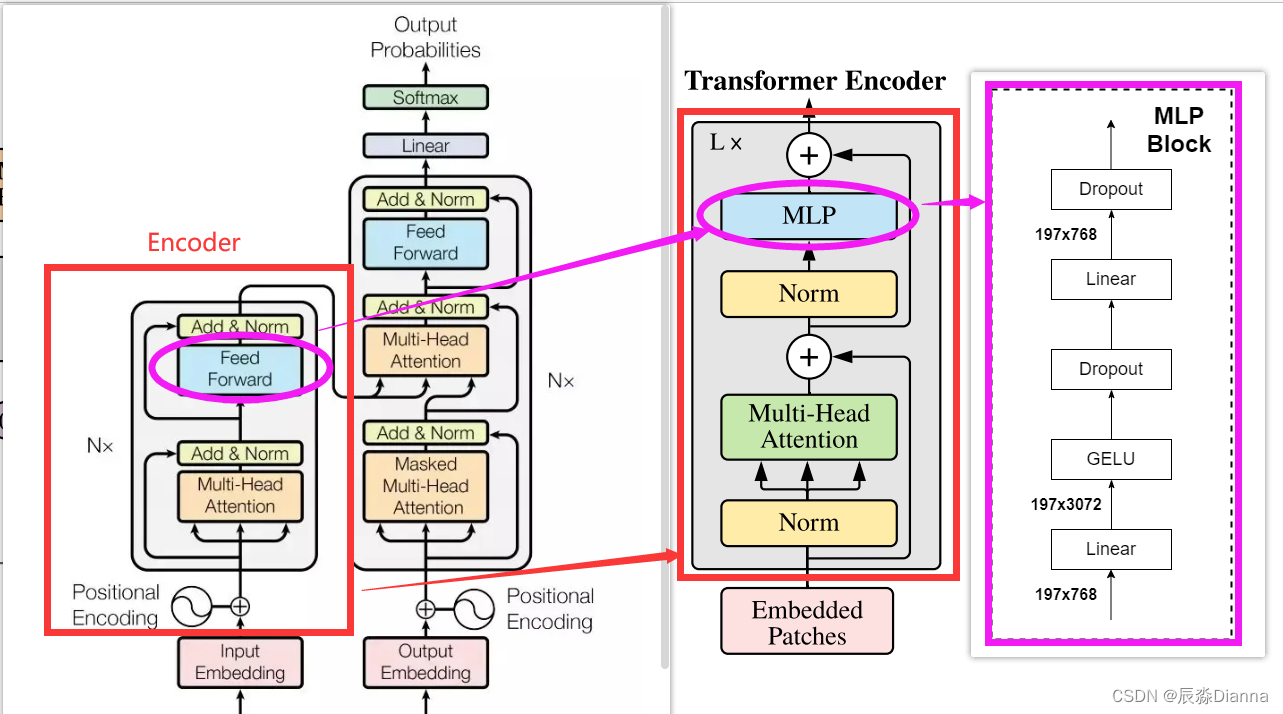
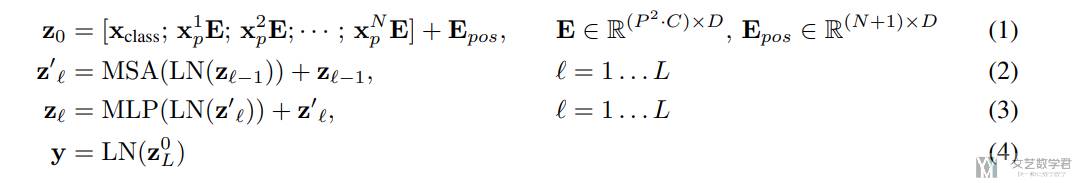Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Schematic illustration of ViT model [58] | Download Scientific Diagram
Build Your Own ViT Model from Scratch
The illustration of the proposed ViT architecture. (a) The main ...
The aggregation and affine graph in different ViT models. (a) The patch ...
ViT model architecture. | Download Scientific Diagram
ViT Model explanation and example how to appied | PDF
PyTorch code Vision Transformer: Apply ViT models pre-trained and fine ...
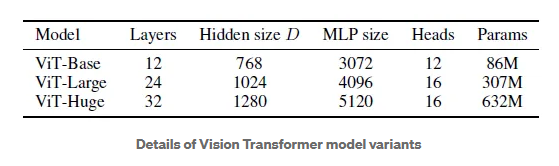
shows the architecture of ViT model in detail. It is based on the model ...
Vit model overview As seen in Fig. 3, We start by dividing the image ...
ViT 模型变体 (一) - 知乎
PPT - leewayhertz.com-HOW IS A VISION TRANSFORMER MODEL ViT BUILT AND ...
Comparison with popular ViT models. Our CF-ViT is built upon LV-ViT-S ...
The Pre-Trained ViT Model. | Download Scientific Diagram
Accuracy Plot of all the ViT Models. | Download Scientific Diagram
| A model-level ensemble constructed using fine-tuned CNN and ViT ...
ViT Backbone for Diffusion Models (U-ViT)原理 - 知乎
Our proposed ensemble of two ViT models [10, 21]. | Download Scientific ...
ConVision Benchmark: A Contemporary Framework to Benchmark CNN and ViT ...
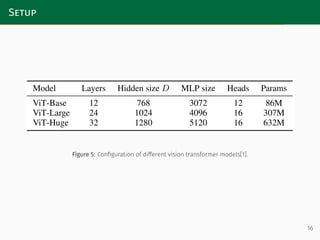
ViT models' general information. | Download Scientific Diagram
The use of the VIT model and the system boundary of the case study ...
ImageNet top-1 accuracy of the ViT models with shared self-attention ...
Training results for ViT models trained on the cifar10 dataset. The ...
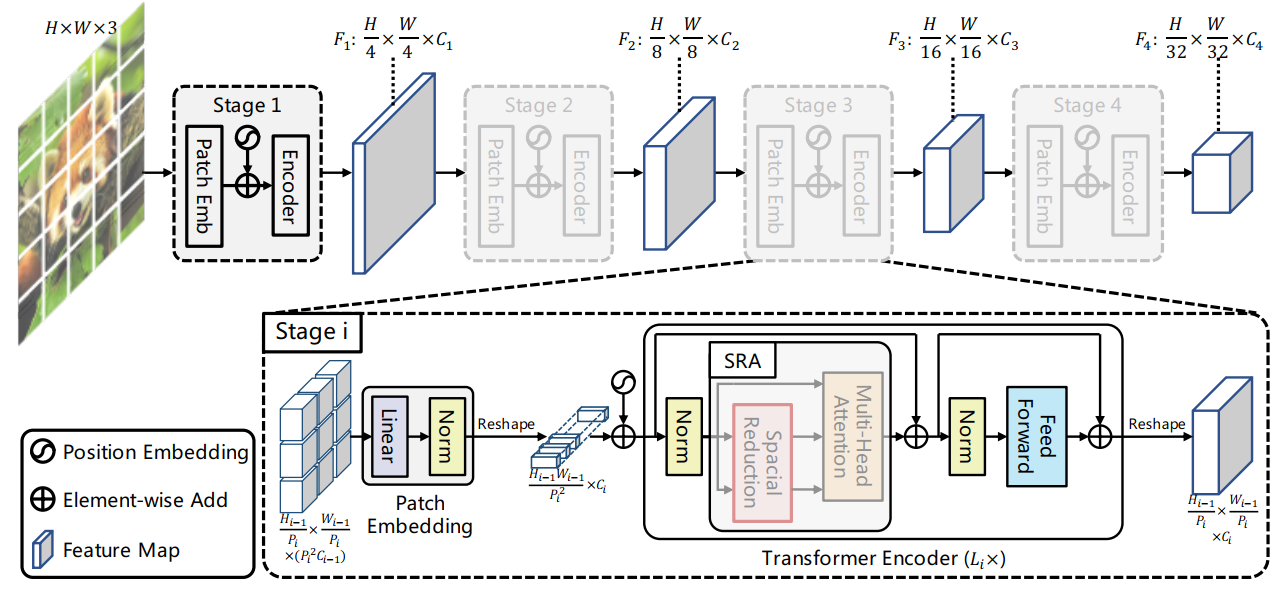
TFormer: A Transmission-Friendly ViT Model for IoT Devices | DeepAI
ViT model's implementation details. | Download Scientific Diagram
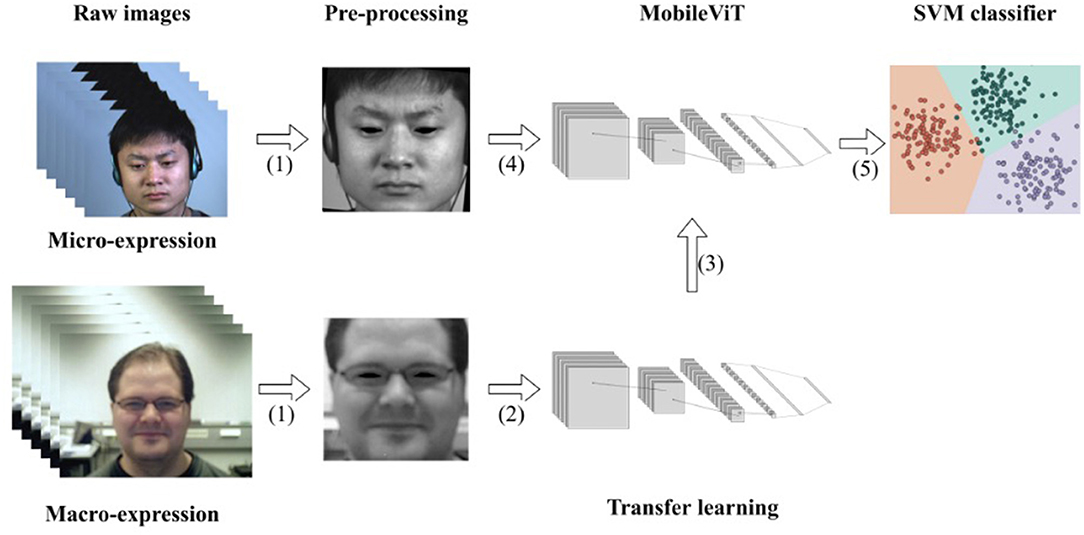
Frontiers | Lightweight ViT Model for Micro-Expression Recognition ...
The aggregation graphs between layers in different ViT models. (a) The ...
Are Generalized Self-Supervised ViT Models the Image Objective ...
Long runs. Soft MoE and ViT models trained for 4 million steps with ...
FIGURE E Comparison of convergence speed of ViT models using Vanilla ...
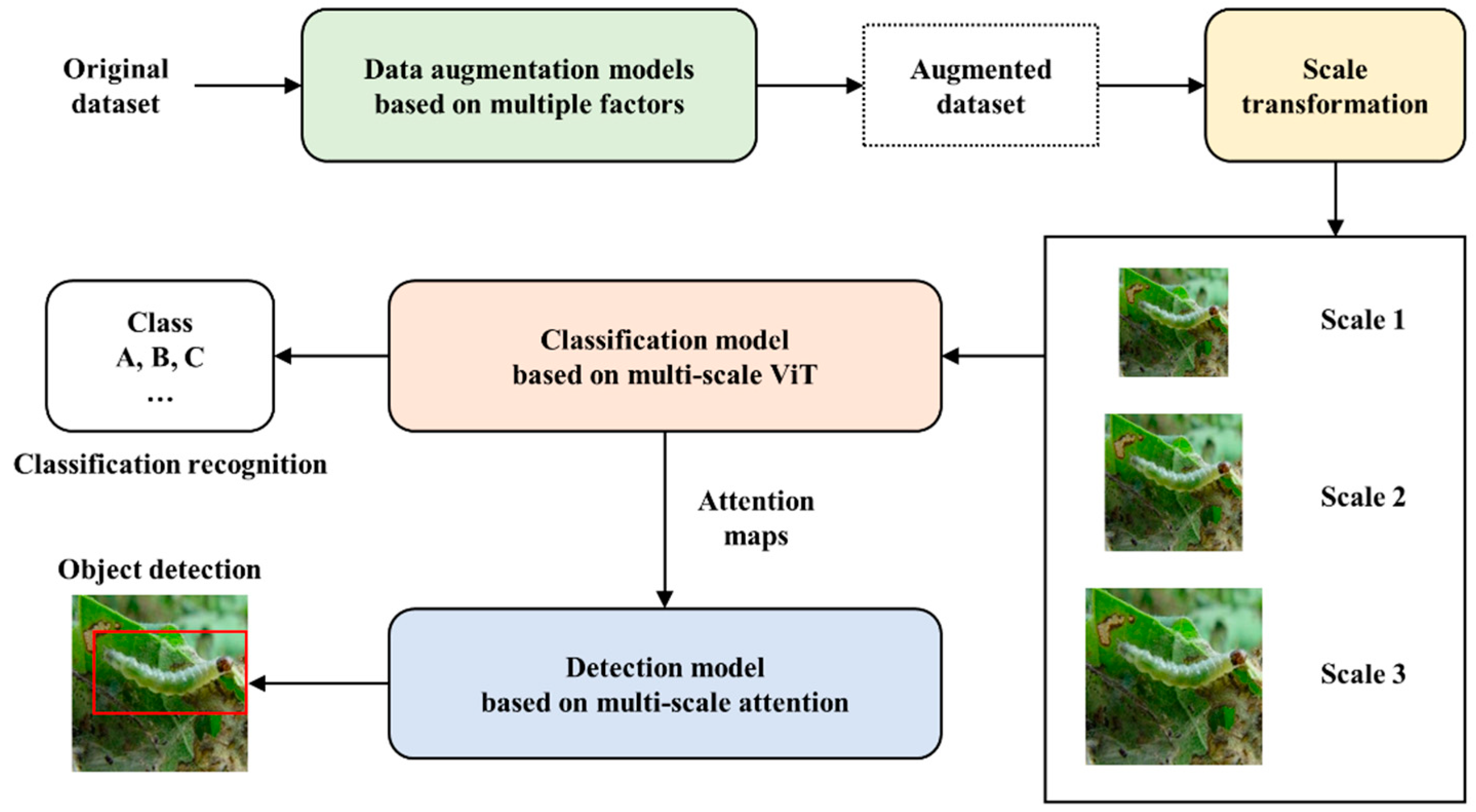
Multi-Scale and Multi-Factor ViT Attention Model for Classification and ...
Overview of ViT model, adapted from [18]. | Download Scientific Diagram
The ViT model extracts image feature process | Download Scientific Diagram
Performance of conventional transfer-learning-based ViT models. BUSI ...
Computadoras VIT: Cómo comprar todos los modelos - Notilogía
ViT model structure diagram. | Download Scientific Diagram
How to load pre-trained ViT models? I can't load it. · Issue #105 ...
Execution time breakdown of the DeiT and ViT models. | Download ...
What is difference between Deit and ViT models here? They looks like ...
Comparison of the supervised ViT model and the composite models under ...
Performance of ViT and ResNet Models on Different Datasets as a ...
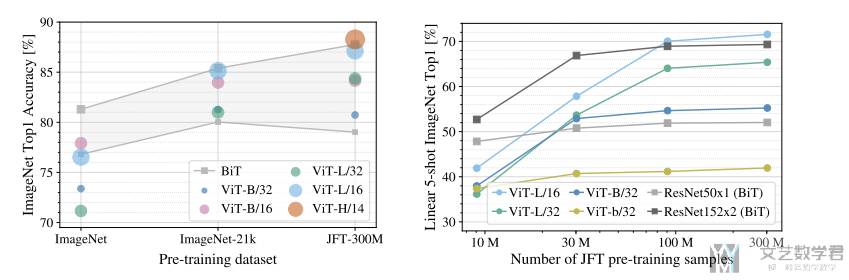
Training large ViT models on ImageNet-1K. For wall time training ...
A single ViT model can provide a features ensemble since class token ...
Vision Transformer (ViT) Notes | Wenwen Kong
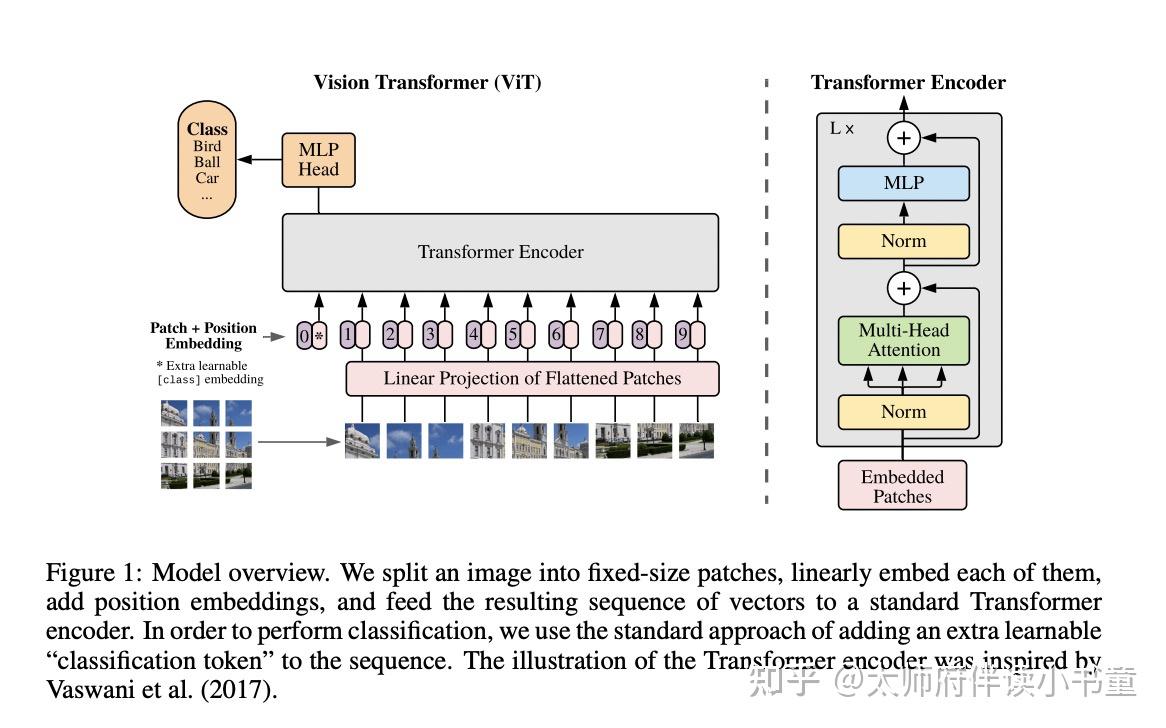
Vision Transformer (ViT)
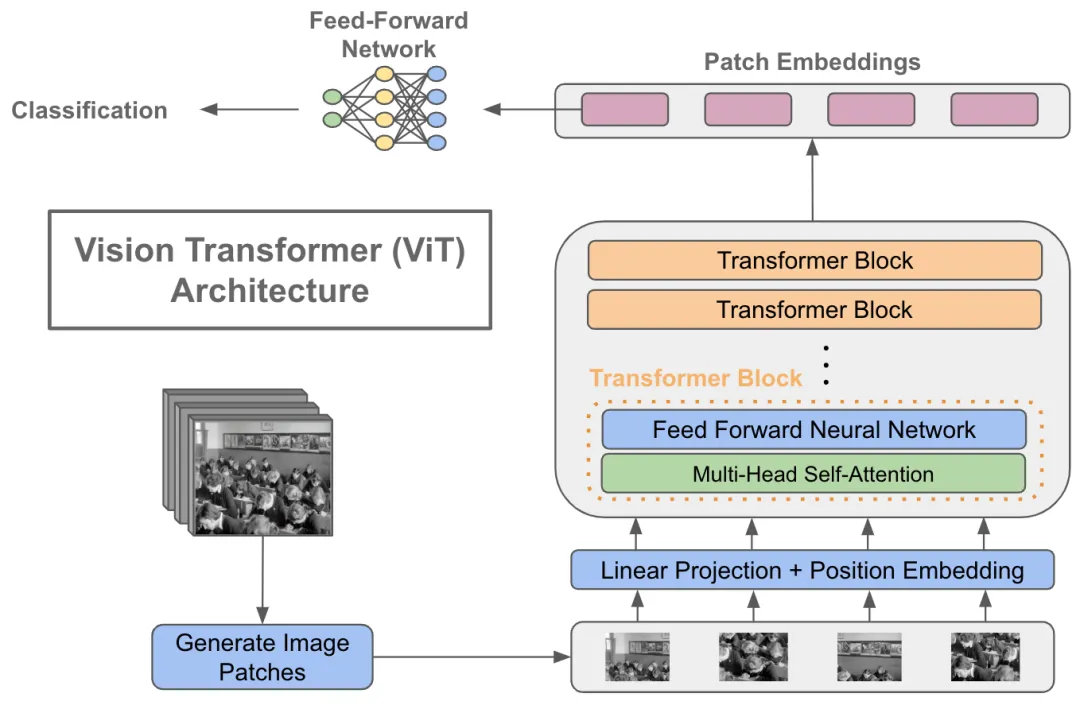
Vision Transformer (ViT) Architecture - GeeksforGeeks
Original pure Vision Transformer (ViT) model [2] adapted for Vascular ...
Vision Transformer:视觉Transformer对CNN的降维打击
Improve Accuracy and Robustness of Vision AI Apps with Vision ...
Vision Transformer (ViT)及各种变体_vit架构-CSDN博客
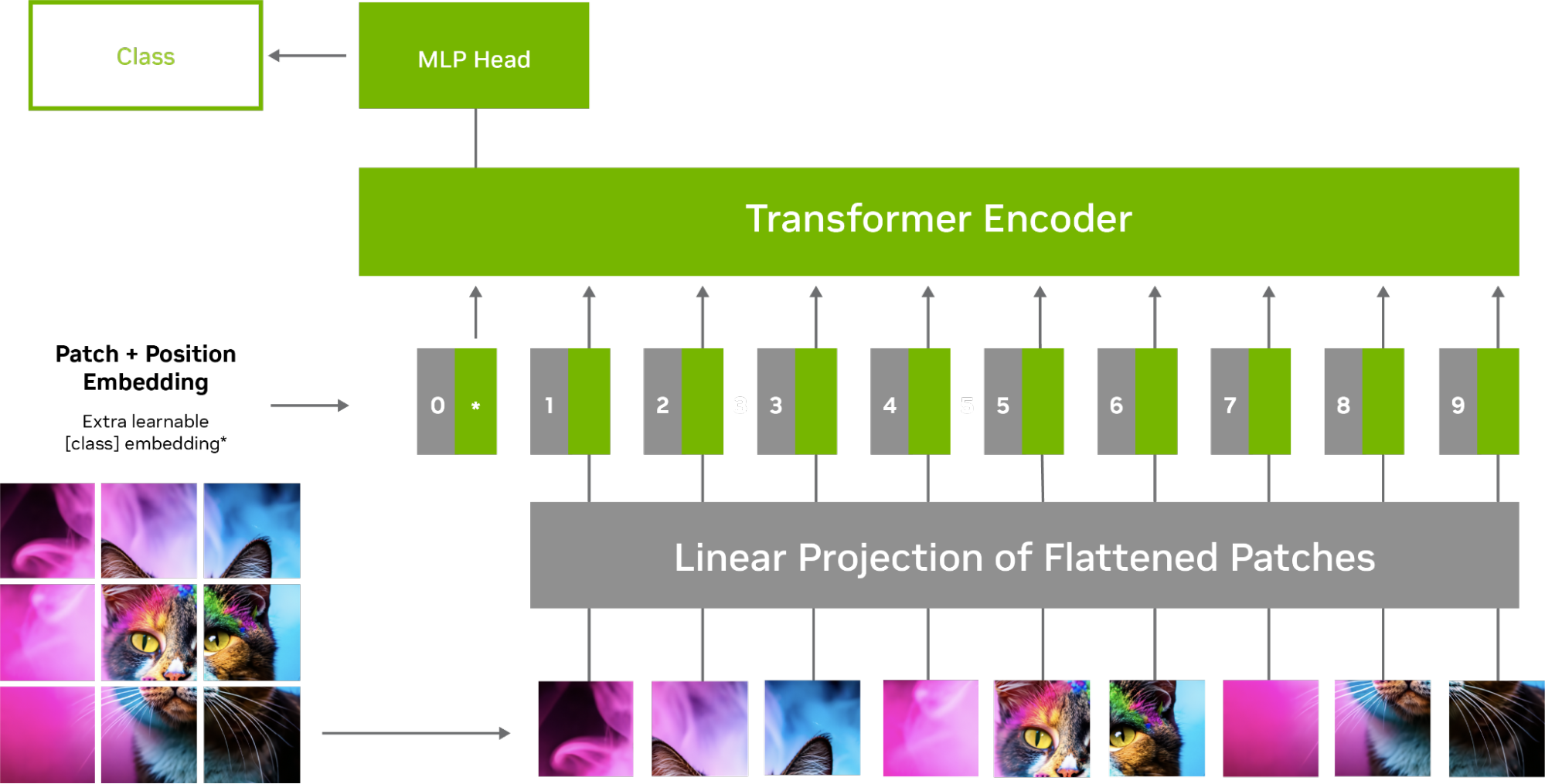
Vision Transformers (ViT) Explained | Pinecone
Vision Transformer(ViT):打通CV与NLP领域的经典之作 - 知乎
(PDF) Vision Transformer (ViT)-based Applications in Image Classification
Google AI Introduces ViT-22B: The Largest Vision Transformer Model 5.5x ...
How the Vision Transformer (ViT) works in 10 minutes: an image is worth ...
Vision Transformers (ViT) Explained | AI Tutorial | Next Electronics
Vision Transformers in Image Captioning - Analytics Vidhya
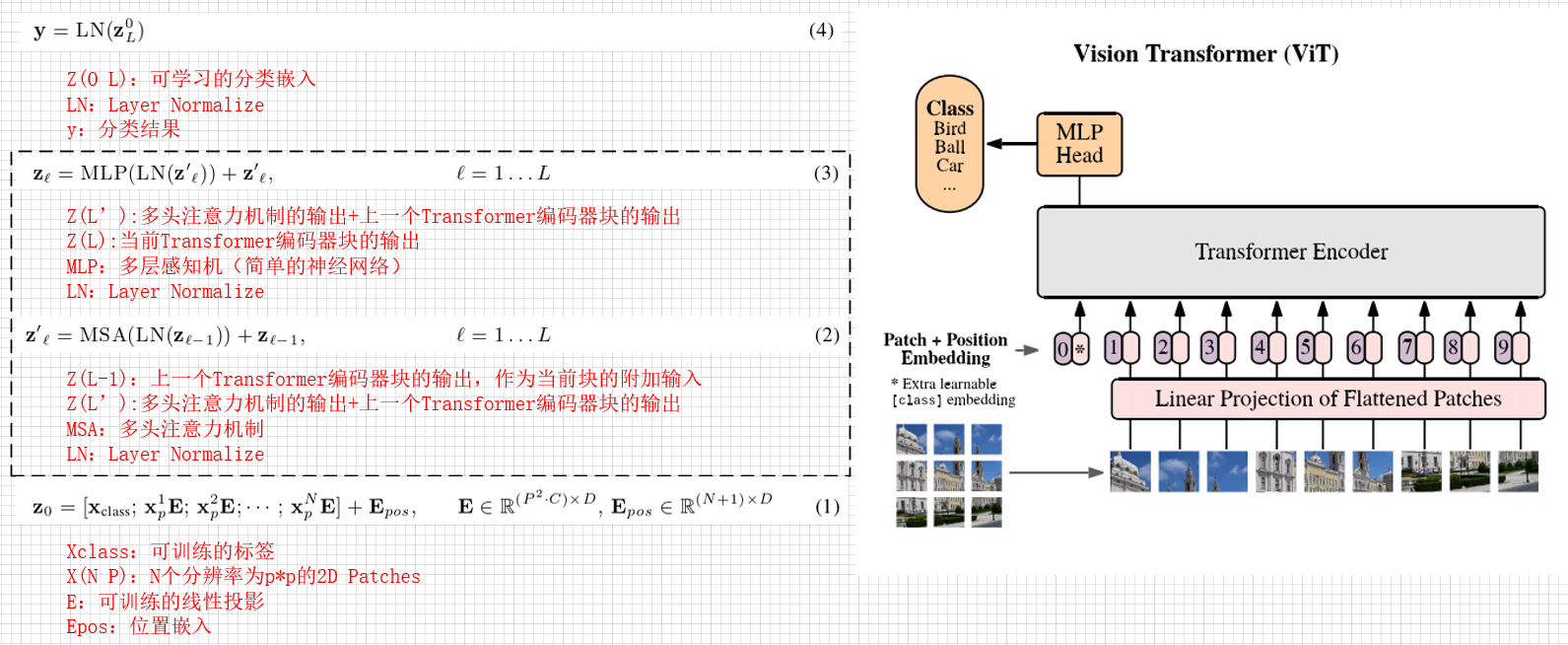
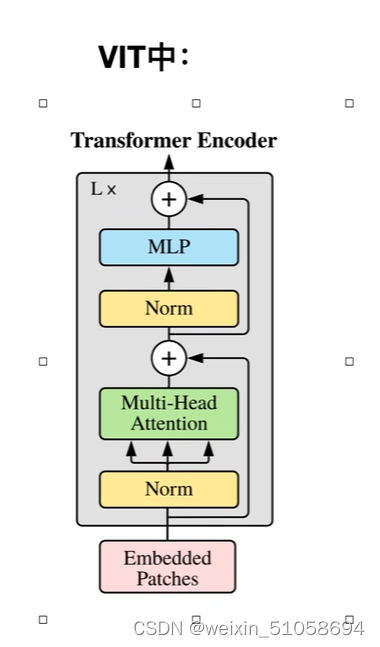
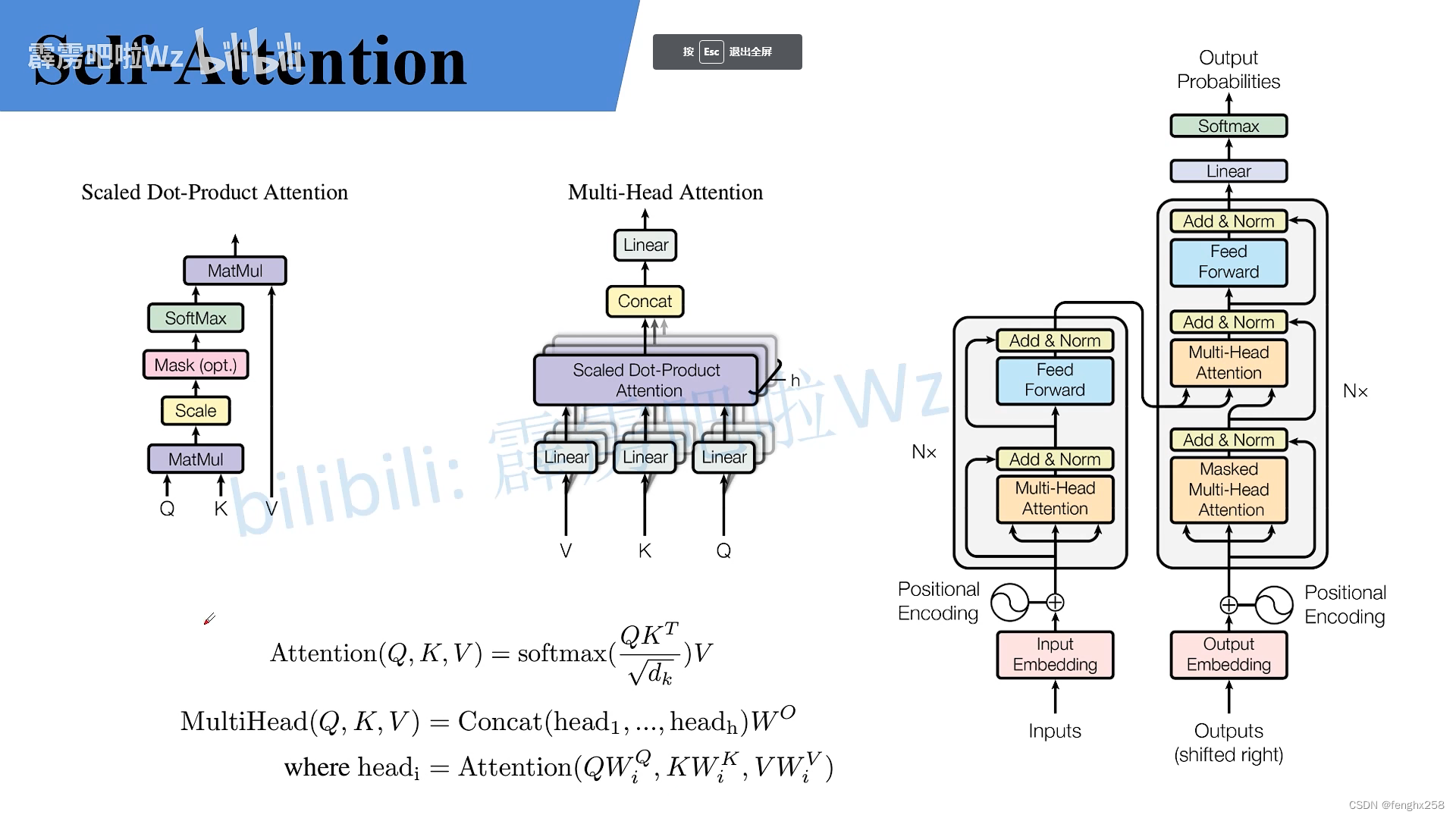
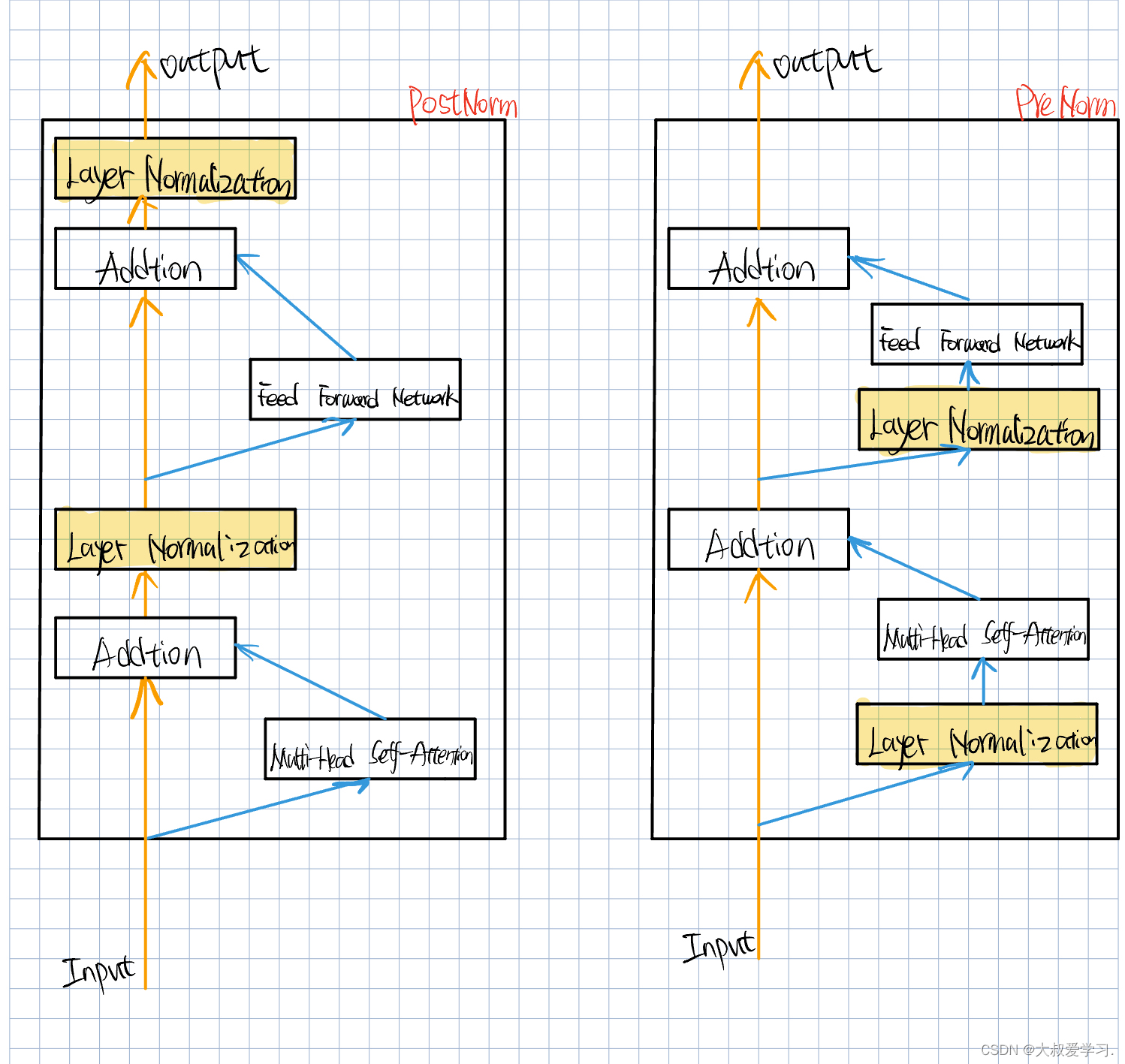
图解Vit 3:Vision Transformer——ViT模型全流程拆解(Layer Normalization, Position ...
GitHub - ali-k-hesar/how-AI-Sees-Our-World: Vision Transformer (ViT ...
GitHub - Ronzosimone/ViT-Models: Implementation of the Vision ...
Vision Transformer (ViT) Paper Explained - YouTube
Vision Transformer (ViT): How It Works and How to Build It in PyTorch ...
21.Vision Transformer(ViT)模型原理及PyTorch逐行实现 - 知乎
How is a Vision Transformer (ViT) model built and implemented? | PDF ...
How is a Vision Transformer (ViT) model built and implemented? | PDF
How to Utilize Vision Transformer (ViT) Models for Image Classification ...
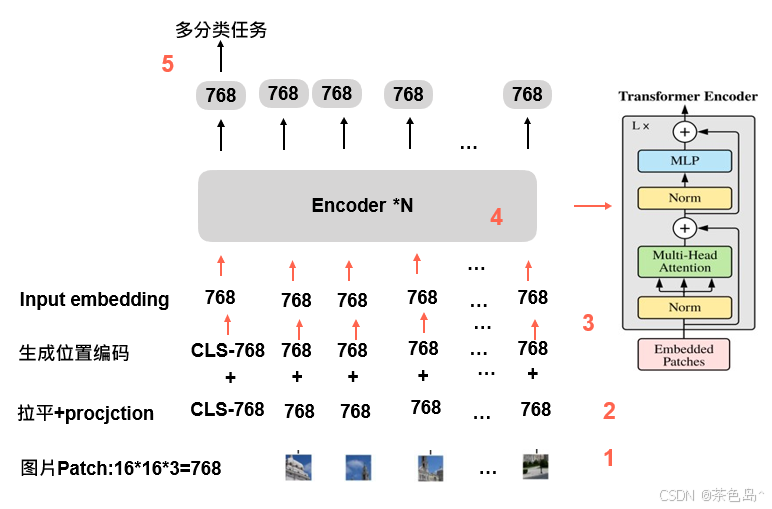
Vision Transformer (ViT) 介绍 | 文艺数学君
Understanding Vision Transformers (ViTs): Hidden properties, insights ...
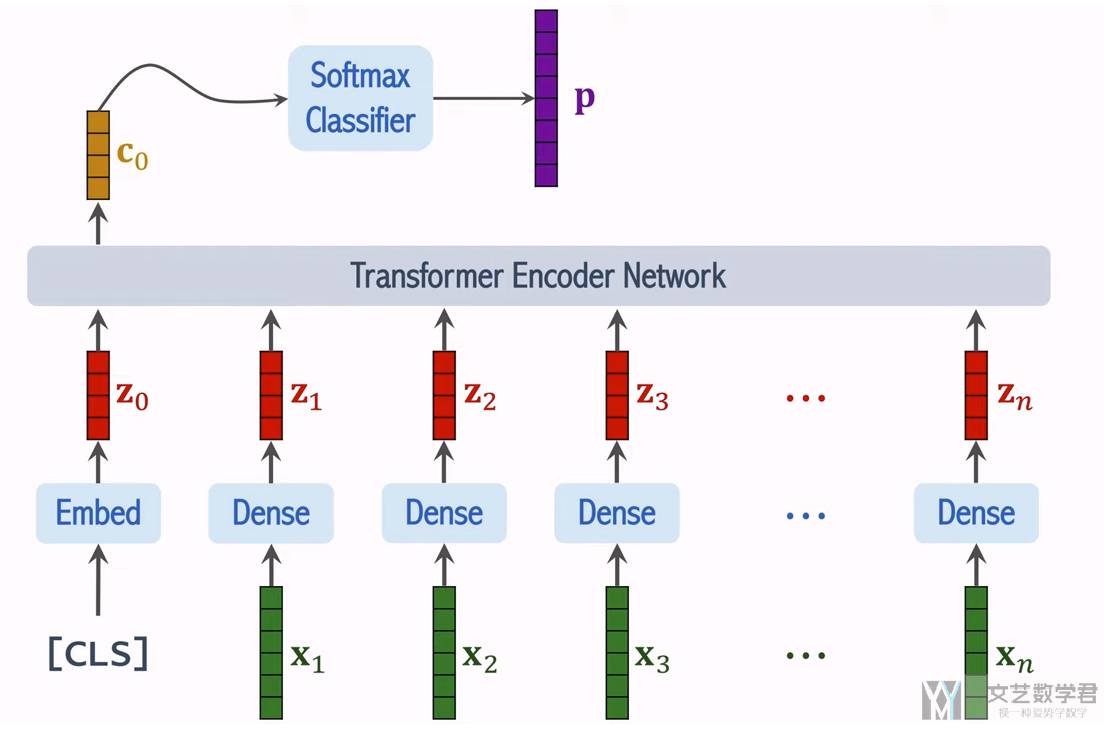
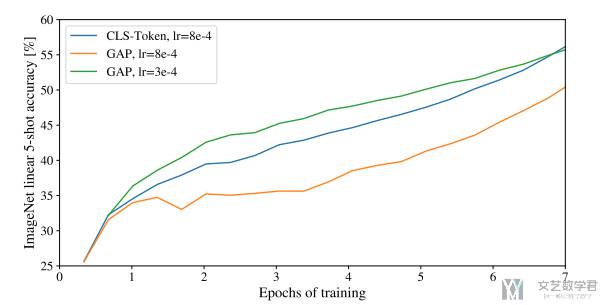
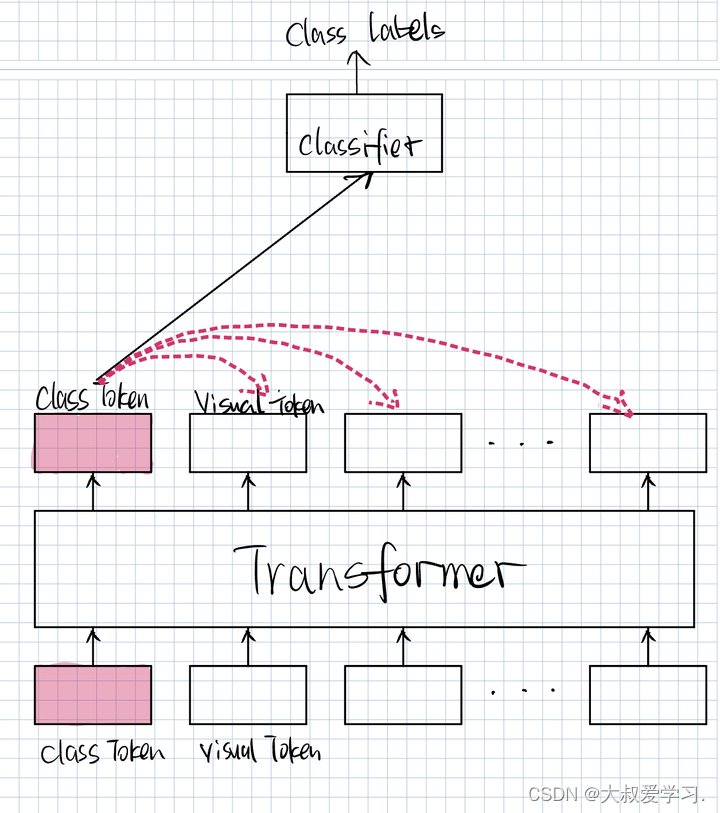
Understanding the Role of the [class] Token in Vision Transformers (ViT ...
(PDF) Vision Transformer Based Models for Plant Disease Detection and ...
ViT(Vision Transformer)论文速读 - 哔哩哔哩
Visual Transformer (ViT)模型详解-CSDN博客
Vision Transformer(ViT)原理详解 + 代码注释_vit的锚框是如何变动的-CSDN博客
Scale Vision Transformers (ViT) Beyond Hugging Face | HackerNoon
Vision Transformer (ViT)初识:原理详解及代码_vit-transformer代码-CSDN博客
Scale Vision Transformers (ViT) Beyond Hugging Face 1/3 - John Snow Labs
EfficientViT: Memory Efficient Vision Transformer for High-Resolution ...
Vision Transformer (ViT) Paper Explanation - YouTube
Vision Transformers Need Registers - Fixing a Bug in DINOv2?
[2305.07027] EfficientViT: Memory Efficient Vision Transformer with ...
论文 “V2X-ViT: Vehicle-to-Everything Cooperative Perception with Vision ...
ViT模型架构和CNN区别_vit transformer比cnn-CSDN博客
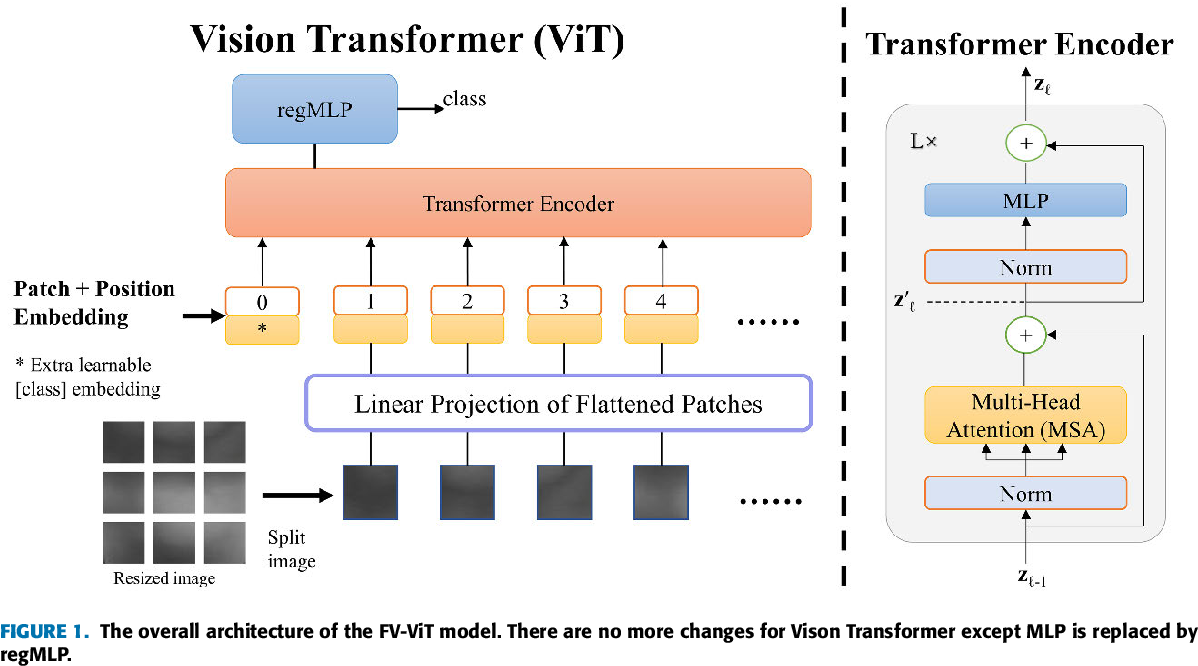
Figure 1 from FV-ViT: Vision Transformer for Finger Vein Recognition ...
CvT:微软提出结合CNN的ViT架构 | 2021 arxiv-CSDN博客
详解VIT(Vision Transformer)模型原理, 代码级讲解-CSDN博客
《Vision Transformer (ViT)》论文精度,并解析ViT模型结构以及代码实现_vit论文下载-CSDN博客
VIT模型从零解读-CSDN博客
The overview of ViT. | Download Scientific Diagram
图解Vit 3:Vision Transformer——ViT模型全流程拆解_vit transformer模块流程-CSDN博客
Vision Transformers ViT: Fine-Tuning with TIMM Library for Image ...
[论文阅读]Vit(Vision Transformer)及代码_vit引用格式-CSDN博客
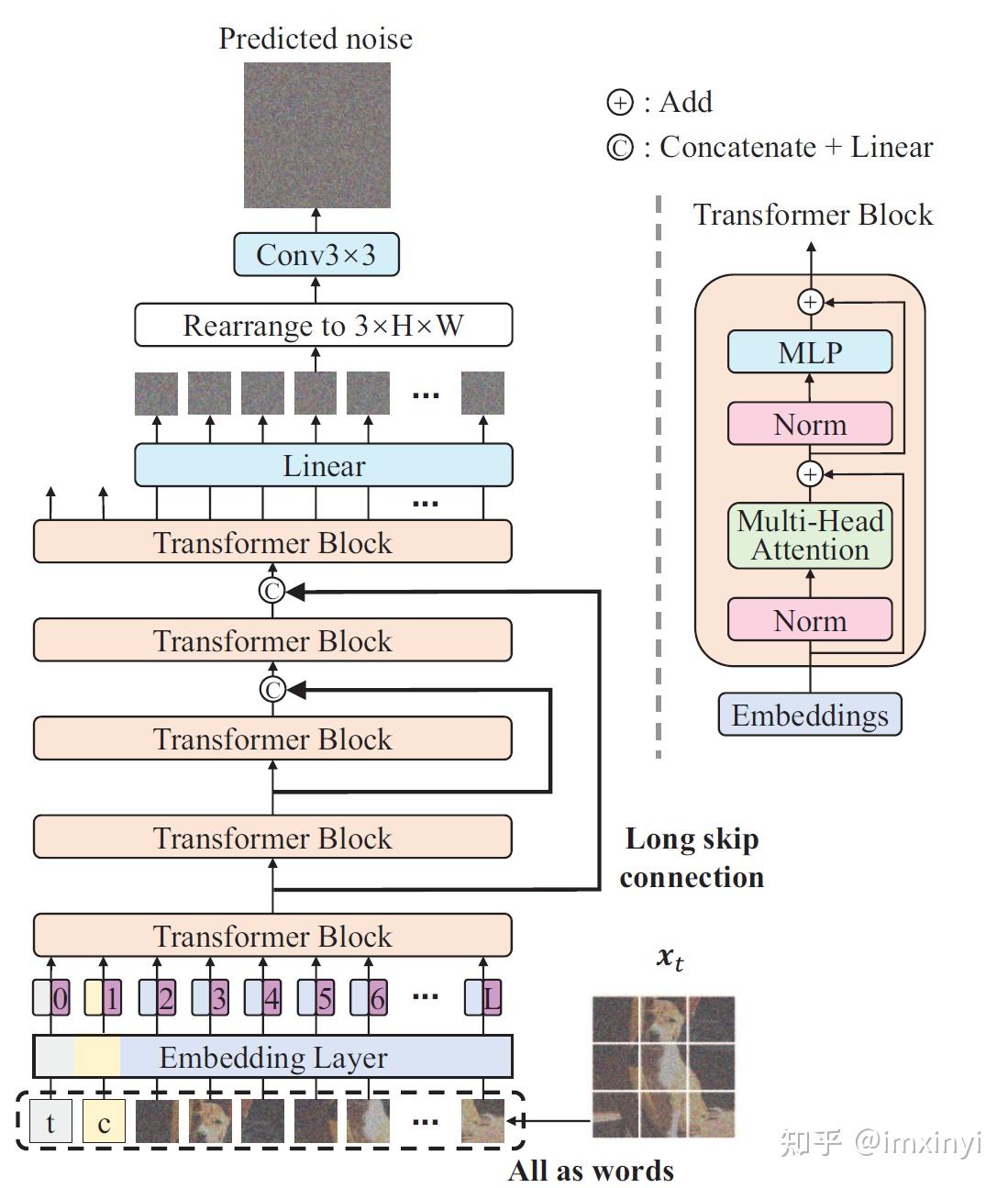
U-ViT(CVPR2023)——ViT与Difussion Model的结合-CSDN博客
VIT(Vision Transformer)学习(三)-纯VIT之swin transformer模型理解_transformer vit中 ...
README.md · google/vit-base-patch16-224 at refs/pr/22
Review — MobileViT: Light-weight, General-purpose, and Mobile-friendly ...
Overview of the proposed n-CNN-ViT architecture. The model is composed ...
Lesion localization using ViT-Patch models. Each row corresponds to one ...
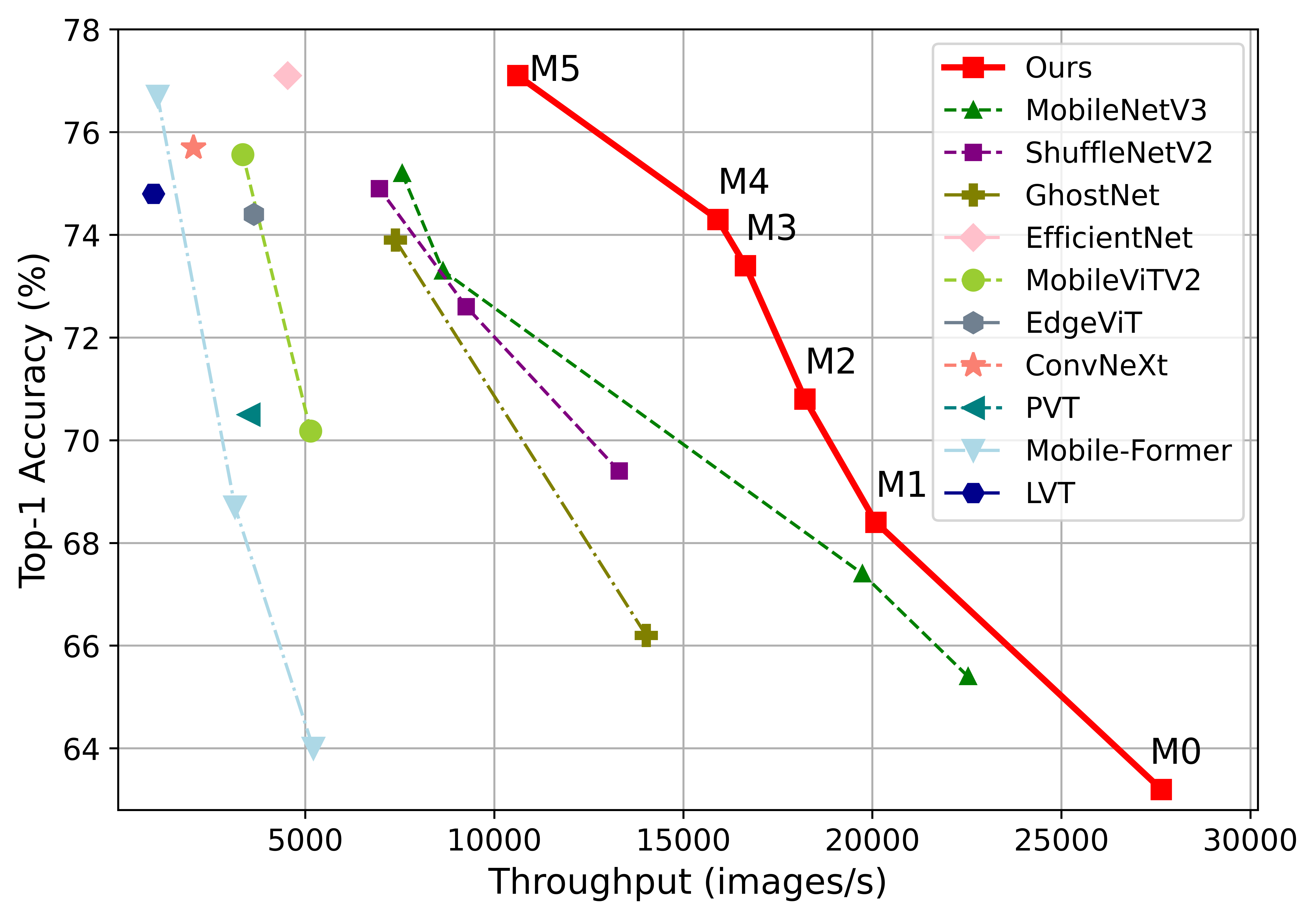
Accuracy and FLOPs trade-off comparison between our SuperViT and ...
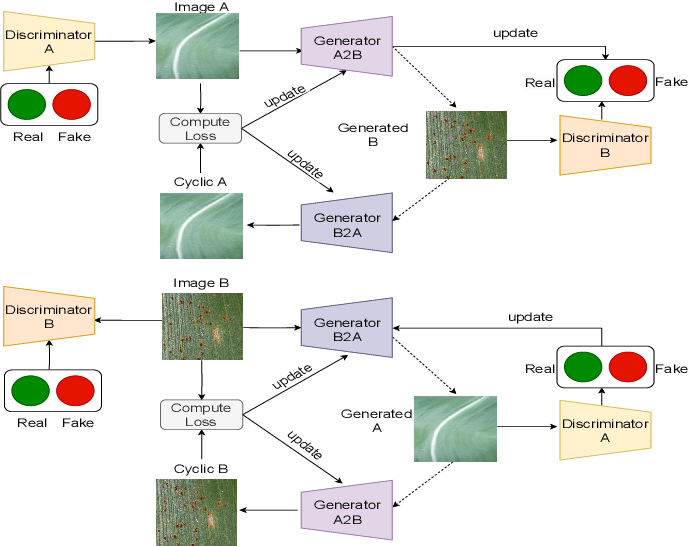
Figure 1 from CycleGAN-Based Data Augmentation with CNN and Vision ...
16. Clustering Features from ViT-B/16 — tsugg
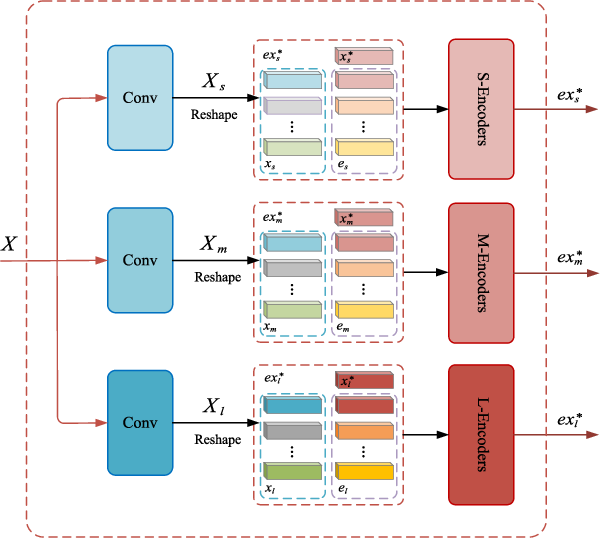
Figure 3 from PolSAR Image Classification Via a Multigranularity Hybrid ...